
Figure 2.1: Example extract from GEDCOM file.
DATE ESTIMATION IN
LINEAGE-LINKED DATABASES
by
Vegard Brox
Bachelor of Science in Computing Science
University of Newcastle upon Tyne
May 2000
Supervisor: Brian Randell
Abstract
Lineage-linked databases are databases that record basic facts about individuals and families, such as date of birth and death and who are the parents of whom. Some of the dates related to the individuals and families in such a database will usually not be known. The aim of this project was to develop a program that would estimate such missing dates in the database, using a number of logical and heuristic constraints. The program was developed in an object-oriented fashion with design in UML and implementation in Java.
I declare that this dissertation represents my own work except where otherwise stated.
This project would not have been possible without supervisor Prof. Brian Randell. He had the initial idea for the project, and has provided many good ideas and useful comments during the project.
1. Introduction *
1.1 Genealogical databases and software packages
*1.2 Date estimation
*1.3 Scope and development process
*1.4 Target audience
*1.5 Plan of dissertation
*2. Background *
2.1 The GEDCOM standard
*2.2 Date estimation
*2.3 Earlier work in the area
*3. Design and development model *
3.1 Design methods
*3.2 Project design
*3.3 Design of GUI
*3.4 Detailed design of estimation process
*3.5 Design for dealing with negative year ranges
*3.6 Development model
*4. Implementation and testing *
4.1 Implementation language and tools
*4.2 Implementation strategies
*4.3 Testing
*4.4 Presentation of program
*4.5 Help system
*5. Results *
5.1 Experimentation
*5.2 Estimation example
*5.3 Negative year ranges
*6. Conclusion *
6.1 What has and has not been achieved
*6.2 What has been learned
*6.3 What could have been done different
*6.4 Future follow-on work
*References *
Books and dissertations
*Web pages
*Appendices *
This project is concerned with lineage-linked databases, also known as genealogical databases. Such databases record basic facts about individuals and families, such as date of birth and death and who are the parents of whom. These databases will almost always have some missing data. There will most certainly be people who are not known at all, which is nearly impossible for a computer to do anything about. More interestingly, it might not be known when people in the database were born, or when they died. The aim of this project was to estimate such missing dates in the database, using a number of logical and heuristic constraints.
This chapter gives an introduction to the project, with a brief explanation of genealogical databases and software packages (chapter 1.1) and the date estimation process (chapter 1.2). It then defines the scope of the project, as planned and achieved and briefly introduces the development model used (chapter 1.3). The target audience for the program and for this dissertation is also specified (chapter 1.4). Finally, it outlines the rest of this dissertation (chapter 1.5).
1.1 Genealogical databases and software packages
Genealogical research is not a new thing. Before the computer age, people would perhaps have a genealogical database on cards, with data about one person on each card, or they would draw a family tree on a large piece of paper. These days, with widespread use of personal computers, most people doing genealogical research prefer to use a computer to hold the data. A number of software packages exist, that allow the user to enter data, view it in a number of ways, maybe even perform certain queries, and most important, store it for later. Most systems will have their own, specific data format they use to store the database but, fortunately, there is a file standard that allows people using different systems to interchange data, provided the software package they use supports this standard. The standard is known as the GEDCOM standard, and it is supported by most of today’s genealogical software packages. By using GEDCOM files as input and output to the program developed in this project, people can keep using their genealogical package of choice, and still use the estimation program developed in this project as an extra tool.
The GEDCOM standard is presented in more detail in chapter 2.1.
Already before the age of computing, some genealogy researchers would try find an estimate for the missing dates in their database. Using common sense and a bit of guesswork, they could be able to find a reasonable estimate. The problem is however, that for a large database, this would be very tedious work, and the lack of real rules to follow would be likely to introduce errors. This project offers an alternative, by letting a computer do the hard work. For this to work, a clear set of rules, or constraints, are needed. An important part of the project was to define those rules.
The estimation procedure itself can be described as a form of mathematical relaxation. It is an iterative process in which the program has to loop through an internal representation of the database a number of times, using the constraints to give a closer estimate for the missing dates each time. How accurately the dates can be estimated depends however on the actual data.
The date estimation process is presented in more detail in chapter 2.2.
1.3 Scope and development process
The scope for the project was to make a working program that performs date estimation. The program should have an easy to use Graphical User Interface (GUI), and it should be able to deal well with error situations. The most interesting error situation is when it is not possible to calculate a meaningful date estimate because of inconsistencies between the input data and the constraints. A part of the scope was also to experiment with it on real-life data to see how well it performs.
To a very large extent, these aims were achieved by the project. The developed program is able to estimate dates, deals well with error situations and has a simple GUI. Some experimentation on real-life data has been undertaken, although this testing would preferably have been more extensive.
The project planning for this project focused mostly on a number of milestones. The development model was a hybrid between the traditional waterfall model and the spiral model. This is explained in more detail in chapter 3.6.
The target audience for the program developed in this project is genealogists who want to do date estimation on their genealogical databases. Extensive knowledge about computers is not supposed to be necessary.
This dissertation is written with a different target audience than the general user in mind. The reader is expected to have a good general understanding of computing science. Knowledge of object orientation and Java is probably an advantage, but not really necessary. Similar, knowledge of genealogy might make it easier to read this dissertation, but the interesting areas are explained anyway.
This is a brief overview of what the rest of this dissertation contains:
Chapter 2 builds on this introduction by explaining in more detail the background to the project. It contains more detailed discussions about the GEDCOM standard and the date estimation process briefly presented in this chapter.
Chapter 3 is concerned with design and some software engineering aspects. The design methods used in the project are discussed, and the actual design is presented. It also discusses the development model used for the project.
Chapter 4 focuses on implementation and testing. The tools and language used for the implementation are introduced, and implementation strategies explained. The finished program is presented, and there is a discussion of the testing that has been carried out.
Chapter 5 gives the results of the project and evaluates them. It describes the experiments which have been undertaken and how well the program performed, and discusses whether the objectives of the project have been reached.
Chapter 6 is the conclusion for the project. It also summarises what has been learned and outlines possible future follow-on work.
In this chapter, the background for this project is discussed. The focus is on the GEDCOM standard (chapter 2.1) and the date estimation process (chapter 2.2) in particular. At the end of the chapter, earlier work in this area is presented (chapter 2.3).
As mentioned in chapter 1, the GEDCOM standard allows people using different genealogical software packages to interchange data. The standard was originally developed by the Church of Jesus Christ of the Latter Day Saints (LDS), or Mormons, who are very concerned about genealogy, and who early saw the use for a standard data format. The LDS church have published its own genealogical software package, called Personal Ancestral File, into which GEDCOM was early incorporated. But the standard was published separately as well, allowing anyone to use it for their genealogical package free of charge, which is an important factor in its success. Today there are no real competitors to this standard, and nearly all genealogical software packages support it.
GEDCOM files are ASCII text files that hold information about any number of people and families. The use of such text files is another important reason for the success of the standard, as such files are already supported on virtually all operating systems. The information is structured in the file, using numbers and special text strings that identify what information is what. At the beginning of each line there is a number that specifies what level the information on that line is. Level 0 indicates the start of a new record holding information for e.g. an individual. The remaining lines for that record will then be level 1 or higher. To record information about e.g. the birth of a person, there is a level 1 line indicating that the lines to follow are about the birth, and then one or more level 2 lines giving information about e.g. where and when the person was born. The numbers are followed by a white space and a special text string indicating what the information on this line is, e.g. "NAME" to give the name of a person, "BIRT" for birth and "DATE" for the date of an event. Then the actual information follows, with things like names, places and dates encoded according to special rules.
The encoding of dates in GEDCOM is obviously of importance for this project. Dates can be specified in a number of ways, with different precision. In the basic case, dates are specified as a date, month and year, as a month and a year or as a year only. Any date specified this way can then be prefixed by a keyword indicating that the event happened before, after or about this date, rather than precisely this date. It is also possible to say that an event happened between one date and another.
A very important part of the GEDCOM code is the linking between individuals and families. Each individual and family record is referenced by a unique ID, specified on the first line of that record. An individual can then have links to one family where this person was a child and any number of families where this person was a spouse. The link is created in the file by inserting a special text string ("FAMC" or "FAMS" respectively) followed by the ID of the relevant family. Similarly, a family can have links to the husband, the wife and any number of children in the family (using the text strings "HUSB", "WIFE" and "CHIL").
Figure 2.1 gives a small example of extracts from a GEDCOM file, with information about one person and one family. The first line specifies that this is the start of the record for an individual, specified by the keyword "INDI". The person has ID I24 (IDs have a "@" on either side of them in GEDCOM). The second line says that John Doe is the name of the person. The third line says that this is a male person. Then, the fourth, fifth and sixth line specified that he was born on the 25th April 1887 in Newcastle upon Tyne. As all that information not can be encoded in one line, the level 1 line only says that information about birth is about to follow, while level 2 lines specify date and place. Finally, the seventh line is a link to the family in which he was a child, and the eighth a link to the family in which he was a spouse. Note that these lines make up a complete, valid person record. If information about e.g. death is not known, it does not have to be specified that it is not known. In the example, after the person record, a family record follows. The number 0 at the start of the line means that this is a new record, and not a part of the person record preceding it. The keyword "FAM" means that it is a family record, and the ID is F14. On the following line it is specified that I24, which happens to be the person in the individual record in the figure, is the husband in this family. The next three lines specify that I35 is the wife in the family, while I93 and I94 are the children. Finally, the last two lines tell us that the marriage took place before November 1912. Note that two lines and the use of level 2 is needed to do so, because more information could have been specified about the marriage.
Figure 2.1: Example extract from GEDCOM file.
Even though this project has used GEDCOM files as both input and output, it has only been concerned about a subset of the standard. To do the date estimation, the program does not need to know e.g. what the name of a person is, and where the person was born. The program does however have to store the ID for later retrieval of the record, and the person’s sex, as the constraints used in the date estimation are slightly different for women than for men. Obviously, the dates that are to be estimated have to be stored if they are already specified in the file, and links between individual and families also need to be stored, to be able to get hold of e.g. the parents of a person.
In GEDCOM, there are a number of events for which it is possible to store dates. For this project, five events were selected for date estimation. Four of those are for individuals: birth, christening, death and burial. The last one is marriage date, for families. Christening and burial will in most cases be quite shortly after birth and death respectively, and at first it might seem a bit odd to include them at all. The reason why they are included is that for data from previous centuries, it is often easier to get hold of accurate values for christening and burial than for birth and death, as the former was often written down in church registers, while the latter were not always recorded anywhere. By including christening and burial, it is therefore easier to do a good estimation on historical data.
As mentioned in chapter 2.1, dates can be specified in a number of ways, and with greatly differing precision, in GEDCOM. For one event the precise date the event happened might be specified, while for another it might only be specified that it happened before a certain year. To be able to estimate dates with this variety of precision in the data, some assumptions and simplifications have been made. First of all, the program only works with years. When month and date are specified for an event, they are ignored. Precise dates in the input file to the program will however still be precise in the output file, so no precision is lost by running the program. Secondly, the program represents all dates as year ranges. A year range consists of two years, the earliest and latest possible year for the actual date. (If both the years are the same, the year range effectively represents a single year.) This approach means that the program will not try to estimate the dates closer than the data allows, i.e. it will not try to "guess" a single year and hence introduce errors in the data.
The actual date estimation process is an iterative process. Using year ranges as described above, the program will give some estimate for a date in its first iteration, then refine that estimate in later iterations if possible. Before the process can start, a year range has to be assigned to each event for all people and families in the database. Dates that are not specified in the input data at all are initially represented as default year ranges. A default year range is a year range with 0 as start and 9999 as end. Even some of the dates that are specified might have one of these base values. For example, a date specified as before 1840 would be represented as the year range 0 to 1840, while a date specified as 1914 would be represented as the year range 1914 to 1914. The program will then start to loop through the data. It does not matter in what order people and families in the database are processed, because this as mentioned is an iterative process which continues as long as necessary to converge. In the first iteration, each person’s year ranges will be made consistent with the person’s own data, parents’ data, children’s data and marriage data, using a set of constraints. In later iterations, more accurate estimates might have been obtained for some of the people or families used to estimate dates for this person, and so applying the same set of constraints again will result in a better estimate for this person. In a sense, the effects of originally specified dates are spreading through the database, one step at a time. When none of the dates in the database can be estimated any closer during an iteration, the estimation process is finished. The values the dates have at that point will be the final estimate. The year ranges have a flag indicating whether they have been changed since creation. Hence, it is possible for the program to know at the end of the estimation which dates it has estimated and which are as they were originally.
The constraints used by the program, and the algorithm that applies the constraints to the data, are presented in chapter 3.4.
During the date estimation process the program might get into situations where it is not possible to produce a consistent estimate because the results of applying the different constraints would contradict each other. What would actually happen is that the start date for a year range would end up being later in time than the end date for the same year range. The year range would become negative, so to speak. The reason for this would be an inconsistency between the constraints and the input data. The inconsistency could be caused by actual errors in the input data or it could be because one or more of the assumptions used by the constraints (e.g. about maximum living age) did not apply to all the people in the database. What to do when a year range becomes negative was an important part of this project, and solutions to it are presented later in chapter 3.5.
Somewhat surprisingly, the only known work in the area is a Master thesis written by Edith Chipo Lwanda at University of Newcastle upon Tyne in 1992. It has the title "Date Estimation in Genealogical Databases" and the aim of that project was somewhat similar to this one. That project was however, as opposed to this one, made as an extension to an already existing genealogical software system called Reunion, a system which was implemented on HyperCard for Apple Macintosh and whose source code was therefore available. The system produced did produce estimates for some test databases, but it had no handling of negative year ranges apart from reporting them. The estimation procedure was somewhat different from this project. For example, christening and burial dates were only used to estimate birth and death respectively, if they were missing, and all subsequent estimation then used the estimated birth and death dates. Also, the estimation was only applied to a set of related family cards one generation at a time, rather than the whole database. Hence the user might have to do the estimation several times for different parts of the database, and these parts will have to be identified manually.
The thesis indicates that it was not easy to add the date estimation feature to the Reunion system. Because of some space problems, the actual script that did the estimation had to be copied around a lot instead staying in one place all the time, and hence the performance was affected. The system was largely complete, but not robust enough for extensive experiments. Also, it seems that there was not enough time for proper testing after the encountered problems. The thesis says that testing with real-life data "would be very useful". The thesis and its description of how things were solved in that project has been used as background information for this project, but this project is not a direct extension to that project, as a number of things have been solved in a different way.
3. Design and development model
The main part of this chapter is a presentation of the actual design for this project. The overall design is in chapter 3.2, the design of the GUI is in chapter 3.3, a detailed design for the actual estimation process is in chapter 3.4, while the design for the dealing with negative year ranges is in chapter 3.5. First, however, the design methods used in the project are presented in chapter 3.1. Towards the end of the chapter, in chapter 3.6, the development model used for this project is discussed.
Quite early it was decided to use an object-oriented development process for this project. While analysing the problem for the project and looking at development strategies, it was decided to use Java for the implementation. (More reasons for that choice is given in chapter 4.1.) Java is a truly object-oriented language, and when the implementation is to be object-oriented, it is a big advantage to have the design object-oriented as well, because it makes the transition to implementation easier.
After deciding to have the design object-oriented, the next step was to decide what design model to use. That choice was rather easy, as UML (Unified Modeling Language) has become the de-facto standard for object-oriented design. The alternatives would include Booch and OMT, but UML is, as the name implies, a unification of several of the early models, including Booch and OMT, and hence it should be somewhat better. UML is well supported with software and documentation, which also counted in its favour.
UML consists of a number of different diagrams, and it is possible to use just a subset of them, depending on the size and the nature of the project. The most important diagram, which will be used for just about any project, is the class diagram. It defines the classes that make up the project. It is normally used to show associations between classes and operations that can be performed by each class as well. In the class diagram, each class is represented as a rectangular box split into three parts. The upper part gives the name of the class, the second part lists its attributes, while the third list its operations. It is optional how much of this information is listed, and in the class diagram for this project presented in chapter 3.2 it has been chosen not to include the attributes, only the operations.
Associations between classes are represented with lines between the boxes that represent the relevant classes. A line without anything more only specifies that there is a relationship between the classes, without giving any more details about what sort of relationship it is. But it is possible to specify the relationship in more detail as well. If one end of the line is made into an arrow, it indicates that the class that is the starting point for the arrow uses or references the class pointed to, whereas the class pointed to does not know anything about the class that points to it. In other words, it is a one-way relationship rather than a two-way relationship. Aggregation is another, slightly different concept that might be specified. If one class aggregates another, it means that it holds one or more instances of that other class. This is in a sense a stronger relationship than the arrow already described, and it also allows multiplicity to be specified, e.g. one instance of one class can hold 1 to n instances of another. Aggregation is indicated by a diamond on the end of the line close to the class that aggregates another class. There are also other kinds of relationship that can be specified, but as they are not used in this project, they are not presented here.
One other UML diagram has been used in this project as well. That is the sequence diagram, which shows in what order things will happen in terms of communication between objects. At the top of the sequence diagram there are a number of small boxes representing instances of classes in the system, where each box has a vertical line going down from it. Communication between objects is then represented as arrows between these vertical lines. The diagram should be read from the top down, i.e. the first arrows from the top are communication that takes place before the arrows further down. A class diagram and sequence diagram for this project are presented in chapter 3.2.
The actual date estimation process was very important in this project. Before starting any implementation, it was therefore natural to specify this process in more detail than other processes. In chapter 3.4, the detailed design for the date estimation process is presented. This design mainly consists of two things – a list of constraints to be used in the date estimation and an algorithm that applies the constraints to the internal representation of the GEDCOM file. This detailed design is not done using UML. The list of constraints would be hard to represent in UML anyway, and having produced the list without using any particular model, it was natural to simply specify the algorithm using informal programming language syntax. The syntax used in specifying the algorithm is somewhat Pascal-like, but does not strictly follow Pascal syntax or any other language. It is however quite structured with indentation, etc., so any person with programming experience should be able to read it. So even though the design in this project is mainly based on use of UML, the detailed design for the date estimation process shows that UML was only used as long as it was considered suitable for the problem. It is not necessarily a problem to mix UML with other formal or informal methods to achieve the wanted design. In this case it was certainly not a problem.
The program was first implemented in command-line version only, while a GUI was added to it at a later stage. The design presented in this subchapter is for the command-line version, while the extensions necessary to get a GUI are presented in chapter 3.3. The reasons for doing the development this way are given in chapter 3.6.
The main operation of the program is logically split into three main parts. First, the input GEDCOM file must be read, and some internal representation of it must be built. The second part is the estimation process itself, trying to make the year ranges as narrow, or precise, as possible. When the estimation is complete, an output GEDCOM file must be written, based on the input file and the new, estimated dates. This is illustrated in figure 3.1
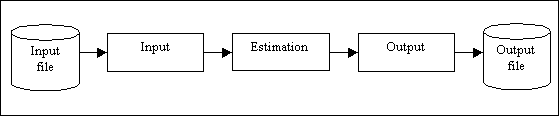
Figure 3.1: Main operation of program
The program was developed in an object-oriented style, so a number of classes were needed. Figure 3.2 shows the class structure for the project, while short, textual descriptions of the classes are given below. The reader should refer to the figure while reading the descriptions. In the descriptions below, a convention has been used where the name of the class that is described in a paragraph is in bold letters the first time it occurs in that paragraph.
The GenealogyDB class encapsulates the internal representation of the input GEDCOM file. Its most important task is simply to hold two hashtables, one for the individuals and one for the families. It has methods for retrieving these hashtables, so that other classes can operate on the hashtables rather than having to do everything through the GenealogyDB class. However, it does have a number of utility functions that, given e.g. an individual identifier, will return e.g. the father of the individual.
One of the hashtables in GenealogyDB consists of Person objects (using each person’s ID as a key). The Person class holds the relevant information for an individual, including date of birth, christening, death and burial. It also has references to families where the person is a child or a spouse.
The other hashtable in GenealogyDB consists of Family objects. The Family class is similar to the Person class, but obviously holds information for a family instead. The data held includes the marriage date and references to the members in the family.
Both the Family class and the Person class have one or more dates to store. But since dates in this context are represented as year ranges, with a start and an end, the simplest way to store this is to have a separate YearRange class. As well as providing the obvious get and set methods, there are also methods to tell whether the range has been changed since its creation and whether it is negative.
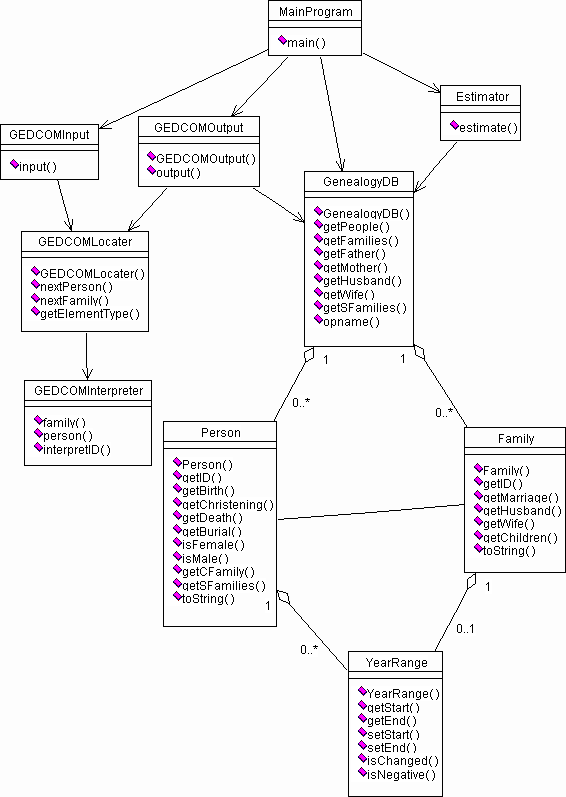
Figure 3.2: Class structure for the project
The Estimator class has a very simple interface, although its operation is not simple. Given an instance of GenealogyDB, it will loop repeatedly through the Person and Family objects held in the database, and apply a set of constraints in order to narrow the year ranges for each date. The operation of the Estimator class is in a sense the "heart" of the system, and its implementation is vital for the success of the system. The algorithm and set of constraints it uses is given in chapter 3.4.
All the classes mentioned so far are in a sense general, because they could be used as a part of any genealogical system. The classes with names starting with GEDCOM, are classes specifically designed for the GEDCOM file standard, in order to read and write such files.
The GEDCOMInput class has the overall responsibility for reading GEDCOM files. It uses the GEDCOMLocater and GEDCOMInterpreter class quite extensively, so not much work is done in this class itself. It provides hashtables for people and families that can later be given to the GenealogyDB class.
Similarly, the GEDCOMOutput class has the responsibility for writing GEDCOM files. It also uses the GEDCOMLocater and GEDCOMInterpreter class, but not as extensively as the GEDCOMInput class does. In order to write a complete file, this class must be given not only the database that holds the internal representation, but also the original input file. It needs the input file because the internal representation only holds a subset of the information from the original file and omits many facts that should be part of the output file.
The GEDCOMLocater class is able to select the lines from a GEDCOM file that are needed in order to build an internal representation of it. So it is this class that does the actual reading of the input file.
The GEDCOMLocater class is not able to interpret the exact meaning of the lines it selects. Instead, it passes them on to the GEDCOMInterpreter class, which is able to interpret the meaning of the lines, and return it in a relevant format (e.g. dates as instances of YearRange).
Finally, the MainProgram class is simply a wrapper for an executable command-line main program that uses many of the other classes in appropriate sequence in order to achieve the goal of the system.
The sequence of communication between instances of the classes (started by the MainProgram) is specified in more detail in a sequence diagram (Figure 3.3). As the diagram shows, the MainProgram starts by asking GEDCOMInput to read a certain input file. GEDCOMInput will tell GEDCOMLocater to locate the relevant data, and GEDCOMLocater will again ask GEDCOMInterpreter to interpret the meaning of the data. GEDCOMInterpreter returns lots of small pieces of data (e.g. single dates) to GEDCOMLocater, which collects them together to form persons or families. GEDCOMInput then collects all the people and families in hashtables, and returns the encapsulated data.
The next operation in MainProgram is to pass the data on to Estimator, which will estimate the dates using the algorithm and constraints specified in chapter 3.4, and then return the data again. MainProgram can then ask GEDCOMOutput to write a new output file. It does this using both GEDCOMLocater and GEDCOMIntrpreter, but in a different manner than GEDCOMInput did. Finally, GEDCOMOutput finishes, and returns to the MainProgram, which then also is finished.
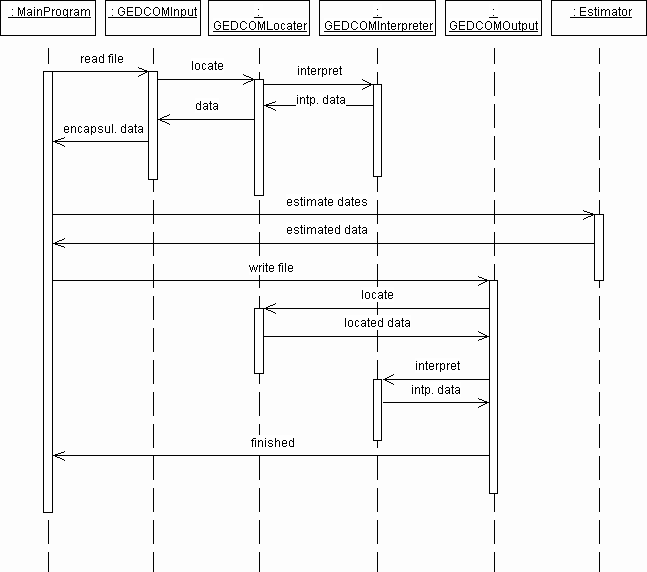
Figure 3.3: Sequence diagram that shows the main operation of the program
In the GUI part of the program, one class usually corresponds to one visual window. In addition, a small main program class is needed to start off everything. A simplified class diagram for the GUI classes is given in figure 3.4, while descriptions of the classes are given below.
The MainProgramW class encapsulates an executable main program which simply starts up the main window in the application and exits the program when the main window is closed.
The class that represents the main window is, naturally, called MainWindow. It contains the GUI for the main window, action handlers for the operations that can be performed there, and most important it also contains the GUI version of the estimation procedure. In other words, this class corresponds to the MainProgram class in the command-line version, whereas MainProgramW does not. Hence the MainWindow class also has references to all the classes that the MainProgram is shown to have references to in figure 3.2. For simplicity, only the references to the other GUI classes are shown in figure 3.4.
The OptionsWindow class is a window in which the user-editable parameters to the constraints can be changed. When the window opens, it reads the values from the file properties.dat, and if the user clicks the OK button after having changed any of the values, the new values will be stored in this file as well.
The MessageDialog class takes a text-string as an input parameter and displays a message box with that text string and an OK button. Hence, it can be used whenever it is necessary to give the user an information or error message.
The AboutBox class is a custom-made about box for this program, and simply displays some information about it.
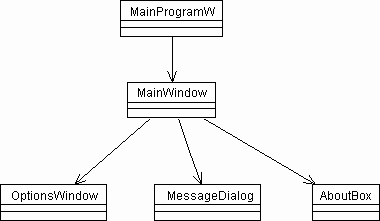
Figure 3.4: Class diagram for the GUI part of the program
3.4 Detailed design of estimation process
As mentioned earlier, the Estimator class is possibly the most interesting single class in the system, as it does the actual estimation. In order to be successful, it needs a clear set of rules, or constraints, which specifies how it can narrow the year ranges. The constraints developed for this project are of the form I >= J + k, where I and J are dates (year ranges) and k is a variable. The constraint can be applied as it stands originally (limiting the start of I), or it can be reversed (limiting the end of J):
Original: I.start >= J.start + k
Reversed: J.end <= I.end - k

Figure 3.5: Constraints for estimating dates
The full list of constraints is presented in figure 3.5. It should be noted that constraints 1 to 7 only involve the individual itself. Constraints 8 and 9 involve the spouse(s) of the individual and should also be used to limit the relevant marriage date. Constraints 10 to 14 involve the parents of the individual, but they should also be used the other way around to limit an individual’s dates compared to his/her children. When doing that, constraint 10 to 11 should be used for males, 12 to 14 for females.
As part of the design process for the project, an algorithm was also established that would apply the constraints from figure 3.5 to the database. That algorithm is presented in figure 3.6.

Figure 3.6: Algorithm for narrowing year ranges
3.5 Design for dealing with negative year ranges
In the initial, command-line version of the program, negative year ranges were detected and reported, but not dealt with in any other way. The way to detect the negative year ranges is to check for negative year ranges after constraining them. In other words, the algorithm in figure 3.6 is somewhat simplified. After each "Apply constraint…", the year ranges that might have been changed should be checked, and if any of them were negative, an exception should be thrown.
With this initial approach to detect negative year ranges, it is quite obvious that to deal with them in a somewhat more sophisticated way, it is possible to just replace the exception throwing with some other mechanism. After some initial thoughts and ideas from the supervisor of the project, it was decided to deal with negative year ranges as described below.
Whenever a negative year range is encountered, it is because of inconsistencies between the constraints and the input data. A "clean" way to deal with this is to determine a subset of the input GEDCOM file that causes the problem, remove it, and then continue estimation on the remaining data. The subset will often consist of more than just the individual or family for which a negative year range was encountered. The subset should be stored to a separate file, so that the user can manually inspect it and try to find out which dates in it can be trusted and which can not. The estimation on the remaining data might lose some precision because of the date that has been removed, but since this part of the data could not be trusted, estimating with that data would be likely to introduce errors. Again, the program follows a somewhat defensive philosophy where it would rather lose a bit of precision than make precise, but false, estimates.
To be able to determine the subset of the GEDCOM that is causing the problem, it is necessary to know exactly what dates have affected the date that the problem was discovered for. All dates that have affected it, and all dates that have affected any of these again, can from the program’s point of view not be trusted. Hence, the individuals and families that these dates belong to should be part of the subset that is to be removed.
The way to be able to tell what dates have affected other dates is to introduce some sort of logging mechanism. The order in which the changes has happened is not of importance, so the log does not need to be in order. The logging mechanism that has been chosen is to have a list for each date that has been changed. The list contains entries that identify what dates in what other individuals or families have affected this date. For easy retrieval later, the lists are stored in a hashtable, with individual/family ID plus some date identifier as key.
It turns out that much of this method of implementing the solution can be done using classes from the standard Java library. There is a Hashtable class available, and the Stack class can do the job as a list of entries, since the ordering is not important. For the entries themselves, a small, simple class called DateLogEntry is needed. It simply contains an ID (for an individual or a family) and a date type identifier. Entries are added to the log in the Estimator class whenever a date is constrained. As mentioned earlier, dealing with negative year ranges also happens in the Estimator class. When a negative year range is encountered, it will retrieve the list of log entries for that date and loop through them. For each log entry it will add the dates that affected this date to the same list, and place the individual or family the date belongs to into the subset that is to taken out. When the list is empty, the subset of individuals and families will be saved to a file, and estimation continues on the main part of the database.
Initially, the development model for this project was mainly in accordance with the traditional waterfall model. In the waterfall model, the tasks to be undertaken are laid out in a sequence, and one task has to be finished before work on the next one can start. The tasks were naturally things like project planning, design and implementation. Strictly speaking however, a couple of aspects were breaking the idea of the waterfall model. Firstly, it was identified from the start that there could be some overlapping between different activities, and in particular the task of writing the dissertation was always planned to go in parallel with other tasks. Secondly, the plan was to first do an initial design and implementation and then carry on with a final design and implementation. The reason for doing so was to get a basic version of the program up and running reasonably quickly, to confirm that the proposed method of date estimation actually worked, and so avoid too much redesign if there was a problem. The tasks of initial design, initial implementation, final design and final implementation could of course all be laid out in a waterfall model manner, but it is to certain degree against the idea of the waterfall model to have more than one stage for design and implementation.
As the project went on, it was identified that the second design and implementation phase would mainly consist of two subtasks. One subtask would be to design and implement a GUI (Graphical User Interface) for the program, the other would be to deal with negative year ranges. Instead of doing the design for both tasks, then the implementation for both, it appeared to be a good idea to do both design and implementation for the GUI first, then do design and implementation for the dealing with negative year ranges. By doing so, the project was effectively changing development from the waterfall model to the spiral model. The idea of the spiral model is to go through a number of iterations, where each iteration consists of tasks like design, implementation and testing. It would have been possible still to place the tasks after each other and claim that the project was still using the waterfall model, but that would be stretching the waterfall model quite far. Still, this proves that the waterfall model and the spiral model perhaps are not as different as one might get the impression when reading literature on the topic. A slightly adjusted version of one model can easily be turned into the other. Hence, the change of development model halfway through the project was not really a problem. The important thing is to know how the actual development is supposed to be for the project. Whether the development generalises into one development model or another is actually less important.
This chapter presents the implementation and testing that has been done in this project. First, the implementation language and tools are presented (chapter 4.1). Then the actual implementation is presented through strategies and examples (chapter 4.2), although the complete source code is too long to include here. Instead it is to be found in appendix B. The next subchapter discusses the testing that has been done during and after development (chapter 4.3), and then the finished program is presented, with screenshots and explanation of how it is used (chapter 4.4). Finally, the implementation of a help system for the program is discussed (chapter 4.5).
4.1 Implementation language and tools
The program developed in this project was implemented in Java. This subchapter starts with a short presentation of Java before giving the reasons for choosing Java as the implementation language in this project. After that, some of the problems with Java are discussed, and finally there is a presentation of the tools used.
Java was developed by Sun Microsystems and released as late as 1995. Hence it is a rather new language, but it has already achieved great success. It is a truly object-oriented language, and builds on the success achieved by earlier object-oriented languages such as C++. But it differs from most languages in certain ways. Most significantly, it is an interpreted language. The Java compiler does not create native machine code for whichever computer it happens to be on, like e.g. C++ compilers do, but rather byte-codes for the Java Virtual Machine (JVM). To run the program, an interpreter is used. Hence, when a program has been written in Java it can run on any computer that has a Java Virtual Machine available. That is probably the most significant reason for all the hype about Java. The cross-platform operation can cut development costs dramatically, and when developing a new operating system, e.g. for a smaller handheld device, there will already be many programs that can run on that new platform, assuming Java support is built in.
Java aims to be a simple, robust and secure language. To achieve that, it has removed some of the features of C++. For example, there are no pointers and pointer arithmetic. (However, objects and arrays are always passed by reference rather than by value.) Wrong use of pointers is very often the reason for hard-to-find bugs in C++, and the pointers are not really needed. Meanwhile, other features have been added or emphasised more strongly. For example, Java has strong type checking and run-time bound checking on array access, and it makes exception handling mandatory rather than having it as an optional extra. Also, Java has automatic garbage collection, so the programmer does not have to worry about memory leakage. It is impossible to give a full introduction to Java here, but the examples above should give people without experience of Java programming an idea of how it differs from other languages.
At the start of this project, the supervisor for the project suggested that it would be a good a good thing if the finished program could run on both MacOS and Windows, even though it was not a requirement. During some initial research, no other systems than Java were discovered that would allow a program to be developed once, and still run on several different systems. By implementing the program in Java, the program would run not only on Macintosh and Windows, but also a long number of other operating systems. As described in chapter 1.1, the use of GEDCOM as input and output for the program makes it independent from any specific genealogical software package. Implementation in Java makes it independent of operating system as well, and hence any genealogist who wishes to do so can in theory use the program.
Getting a cross-platform program was the most important single reason for choosing Java as implementation language for this project, but some of the other Java features also made it very interesting. As Java is object-oriented, you get all the advantages that object orientation are known to give. For example, it is easier to maintain a view of the project and to know where the code for a specific task is placed, which makes it easier to make changes when needed. Another important aspect was the plan to make a basic version of the program first, where the important thing was to see that the strategy chosen for date estimation worked, rather than making the program very nice and user friendly. In Java, it is easy to make a command-line program, and then just add a GUI (Graphical User Interface) to it later, so the focus could be where it was needed. Furthermore, the only software that is really needed to do development in Java is available for free, which obviously makes life a lot easier.
Not every thing about Java is simple, easy and nice though, and not surprisingly, this project ran into some obstacles on the way. First of all, unless you are prepared to pay a large amount of money for some extra development tool, everything, including the GUI, will have to be coded from scratch rather than having a visual tool generating parts of the code. There are also some more problems related to the GUI. The idea behind Java is to develop something once, and then have a good GUI on any platform. But because of the need to make things general, it is often hard to get things to look as wished, and there is certainly a risk of ending up with a GUI that looks mediocre on all platforms. The biggest problem that was encountered has however to do with the different versions of Java that are available. The first version of Java was Java 1.0, then came Java 1.1, while the latest version is 1.2, which confusingly is also known as the Java 2 platform. Java 1.0 had quite a few problems related to it, and is not really used any longer. Java 1.1 is however still widely used. The Java 2 platform has a lot of new features, some of which would have made the development for this project a bit easier, and the end result better than if using version 1.1. For example, there is a built in function for creating nice message boxes for e.g. information and error messages. In version 1.1 the programmer would have to create such boxes from scratch, and the end result is not likely to be as good. The problem with version 1.2 is however that it is not yet widely supported. To run Java on a computer, there must be a Java interpreter available, and Sun, the makers of Java, only provide interpreters for the various flavours of Windows, Sun Solaris and Linux. They allow other companies to make their own Java interpreters for any system, and even provide them with the information necessary to do so, but it still takes time before a new version is supported on most systems. Most important, the latest Java interpreter available on MacOS is at the time of writing still only 1.1 compliant. Hence, by doing the development for version 1.2, much of the cross-platform advantage of choosing Java in the first place would disappear. As a result, the decision was taken to do the development for this project with version 1.1, with extra work and perhaps lower quality GUI as a result.
The only development tools that are really needed to do Java software development is the Java Development Kit (JDK) and a text editor. The JDK is available for free from Sun, provided you use one of the supported operating systems. The JDK consists of a number of tools, including compiler, interpreter, debugger and a documentation generation tool. It also contains the standard Java class library with documentation. Apart from the JDK, a text editor to write the code in is obviously needed. Any text editor, including the Windows Notepad, would in theory do, but one that is a bit more targeted towards programming is certainly an advantage. For this project, the Programmer’s File Editor was used. It was developed by Alan Philips from Lancaster University, and is available for free as well.
This subchapter will explain some aspects about the implementation of the program developed in this project, in particular what strategies have been used for programming style and comments.
In software engineering, it is important to keep a certain style on the programming, and follow a number of "good practices". The idea is that this will reduce the number of errors in the code, make the errors that still are there easier to find, generally improve the readability of the code and make the code easier to maintain. For a big, serious project, there will usually be written code standard that explains in detail how the code should be structured. As a single person did the development for this project, there was not really any need for a code standard to be written down, but still a certain code standard was very much followed. Some of the aspects of this standard are explained below.
Naming of classes, methods, constants and variables is one important aspect of a code standard. Java is a strictly case-sensitive language, so it is important what case is used as well. In general, names are lowercase, but if they consist of several words, the first letter of each word is capitalised. However, method and variable names always start with a lowercase letter, while class names start with an uppercase letter. Exceptions apply when the names contain an abbreviation that is normally written in uppercase, e.g. GEDCOM. Constants follow a completely different scheme, with the whole name in uppercase and an underscore ("_") to separate words. Private variables in a class always has a name starting with "my" as a prefix to separate them from local variables in the methods in the class.
In Java, curly brackets ("{" and "}") are used to identify blocks of code, just like in C++. For this project, the convention of always placing the curly brackets on a new line has been used, both for opening and closing curly brackets. The code between these brackets is indented three spaces.
There is some disagreement about what is best programming style when it comes to where local variables should be declared. Some programming languages force the programmer to declare all local variables at the beginning of a method, while others, including Java, allow variables to be declared at any point during the method, usually just before they are used for some purpose. As a personal opinion, the latter style produces more elegant code, and hence that is the style that has been used in this project.
Another style feature that has been used is to insert white spaces at certain places in the code to make it more open, and hence improve readability. For example, a white space is usually inserted after an opening parenthesis, before a closing parenthesis and on either side of an arithmetic operator.
Regardless of the more detailed style that is described above, the use of comments is absolutely vital to get understandable and maintainable code. This project uses a notation where comments are placed on lines of their own, rather than towards the end of lines containing code as well. Also, the comments are mostly explaining the next few lines, rather than one single line, although there are exceptions. This approach has been chosen because comments on the same line as the code tends to be too low level, i.e. explaining in detail what that line of code is doing but not what the purpose of doing so is. Hence it might be more difficult to get a total view of what a section of code does. The comment style used for this project might require a bit more programming and language knowledge from the reader, but in most cases it is programmers with such knowledge who need to read and understand the code anyway.
In addition to the comments that explain smaller blocks of code, a special type of comment has been used before each class and each method. These comments explain what the class or method does and (for methods) what parameters it takes, what the return value is and what exceptions it may throw. The comments are obviously useful when reading the code directly, but they can also be used in a more elegant way. As long as these comments are written in accordance to a set of rules, a tool called javadoc can be used to generate HTML documents with documentation for the class. The javadoc tool is a part of the JDK, and works a bit like a compiler in the sense that it takes a number of source code files as input. The difference is that it does not produce an executable program, but rather a set of HTML documents. The tool reads the code as well as the special javadoc comments, so if the tool is given a file without javadoc comments, it will still produce an HTML document that lists the methods in the class with their parameters and return type. By supplying the javadoc comments, the programmer’s explanations will be added as well. The resulting HTML documents are similar to the HTML documents Sun provide as documentation to the standard Java class library. Figure 4.1 shows an example of javadoc comment for a method in a source file. The javadoc comment block starts with "/**" on a line of its own. Each subsequent line in the block then starts with a single "*". First in the block, a textual description of the method is given. Then, so-called tags are used to identify what the remaining information is. For example, "@param" indicates that this line gives information about a parameter to the method. The name of the parameter and a description of it follow. The actual method follows immediately after the javadoc block. The HTML documents containing the documentation produced for this project are available in appendix A.

Figure 4.1: Example of javadoc comment in source file
The testing for this project has been done in several different ways and at different times during the after the development. During development, each complex class was tested by e.g. printing out intermediate and final results to the screen. Some of the code needed to do so was inserted into the code for the class and later removed when it was tested and worked the way it should. For example, the GEDCOMLocater class printed out the lines it had located, which would later be processed. The GEDCOMInterpreter was not yet implemented at that stage, but by doing this printing, the locater class could be tested on its own, i.e. a unit test. Later in the development, when more classes were implemented, it was possible to do an assembly test, i.e. a test of a group of classes that still is not the whole system. For example, it was checked that all the classes dealing with reading the GEDCOM file and the database classes worked properly by printing the contents of the database after reading the file. The actual estimation was at this point still not implemented, but by doing an assembly test, it was checked that the estimator class would receive the correct input. To print the contents of the database, a separate class was implemented, called DebugOutput. The main program (command-line version) created a database, using the input classes to read the file, and then passed on the database to the DebugOutput class, which printed all the contents. A similar assembly test was done after the Estimator class was implemented, but before the output module was, and hence it was possible to see that the date estimation worked before the writing of a new GEDCOM file was implemented.
When the whole command-line version of the program was finished, the first system test was done. A system test is a test of the whole program, and hence no debug output should be used instead of the real, expected input and output. Still, this was an early version, without a GUI and without any handling of negative year ranges, apart from detecting them. That actually made it easier to do this testing, because it was easier to find out what was causing trouble when the extra features were not there yet. The command-line version of the program expects the name of the input and output files as command-line arguments, and even in the finished version it is also possible to give the string "DEBUG" as an extra parameter to get the debug output produced by the DebugOutput class. During and after implementation of GUI and handling of negative year ranges, new unit and assembly tests were done, for example to see that the GUI looked OK before connecting it to the rest of the system so that it actually did something. Then, new system tests were carried out on the updated version of the whole program.
After finishing implementation, it was also natural to do system tests on different operating systems, to check whether the program was as cross-platform as it was supposed to be. Windows 98 and Sun JDK 1.1.8 (which is the latest development kit for Java 1.1) were used during development, and hence were already tested. The program was tested on Sun Solaris with Sun JDK 1.1.7, and worked without any problems at all. For Linux, Sun have only recently started to support the operating system with development kits, and for Java 1.1 there are only ports available. The program was tested on Linux with the Blackdown Java-Linux port version 1.1.6, and although the program started without problems, it would crash whenever a message box was closed. As Java is backward compatible, the program was also tested with a pre-release of version 1.2 (for the Java 2 platform) of the same port. With this interpreter, the same situations would cause the program to "hang" for a couple of seconds, but then continue operation as normal. Because of time limitations, it was not possible to do any detailed investigation into the reasons for this behaviour. However, as the problem does not occur under Sun’s official versions for Windows and Sun Solaris, it will have to be assumed that the problem is caused by a bug in the Blackdown Java-Linux port, rather than in the program developed in this project.
Testing on other operating systems than Windows 98, Sun Solaris and Linux was somewhat hampered by the lack of availability of Java interpreters on the relevant computers. The UCS Windows NT does not have a Java interpreter installed, and normal users do not have the privilege to install one. There should however be no problems with the program under Windows NT, as the version of the Java interpreter used by it is the same as for Windows 98. On MacOS, the situation is somewhat different. There is a version of the MacOS Runtime for Java (MRJ), which is Apple’s port of the Java interpreter, installed on the USC Apple Macintoshes. However, it appears that only the part that is required for running Java applets is installed, not the part that is required to run Java applications. Again, a normal user does not have the privilege to install this. At the time of writing, the program was still not tested on MacOS, but investigation into other ways of getting access to an Apple Macintosh with the required software was still on-going.
The lack of availability of the Java interpreter on the UCS computers has been somewhat frustrating. As a personal opinion, an updated Java interpreter should be available on virtually all computers in a big university like University of Newcastle upon Tyne.
This section will give a little walkthrough of the program, with screenshots and explanations of how to use it. The GUI for the program is very simple, as the most interesting parts of the program are operations you not can see. Still, it was considered important to have a GUI rather than a command-line version only, as it makes it easier for people with less computer experience to use the program.
The main window is very simple, consisting of two buttons, a menubar and a status window. It is shown in figure 4.2. The menubar contains the two operations that are available as buttons and a couple of others, for example access to the about box.
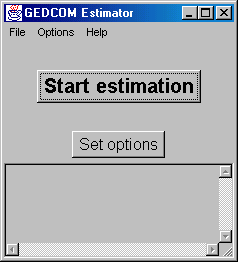
Figure 4.2: The main window
The "Set options" button will bring up a new window shown in figure 4.3. The values shown in this window are used by the constraints in the estimation procedure. The default values provided will often be good enough, but if the user knows that the data he/she would like to perform estimation on are of a different nature, the values can be changed. For example, if the database only contains data from earlier centuries, the user might want to run the estimation with a lower maximum living age to try to get more accurate estimates. The values are stored to a file, and hence after changing a value, it will still have the new value next time the program is started.
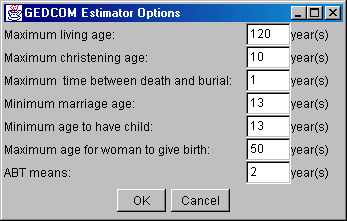
Figure 4.3: Options window
Assuming the user selected the "Start estimation" button in the main window, the sequence of events that makes up the estimation procedure is given below. First, the user will be asked for an input file through a standard file dialog window with the text "Select input GEDCOM file:" shown in figure 4.4. Note that the dialog may look different depending on what operating system is used.
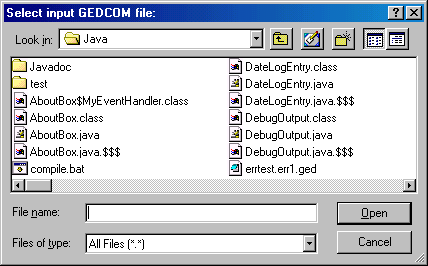
Figure 4.4: File dialog for input GEDCOM file
After the user has specified a file, the program will then attempt to read the file, create an internal database from it, and do the estimation. All this is done without any further interaction from the user, but the user can still see what is going on by looking at the status window in the main window, which will be updated with short messages as figure 4.5 shows.
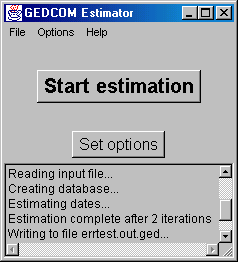
Figure 4.5: Main window with status messages
If any negative year ranges were encountered during estimation, the program will take out one or more subsets of the original GEDCOM file and store them in separate files. Each subset will contain at least one inconsistency, either because there actually is an error in the file or because one or more of the options are set to a too strict value (e.g. setting maximum living age to 10 years will give negative year ranges for most databases). The program will automatically store the subset files in files with similar names as the input file, but with "err1", "err2" etc. added to it. The user will get a message box like the one shown in figure 4.6 if any negative year ranges were encountered.
Figure 4.6: Message about negative year ranges
The last thing that happens is that the user will have to specify where the new output file should be stored. This is done through a file dialog again, but this time with the text "Save the output GEDCOM file as:" shown in figure 4.7. The program will save the GEDCOM with the updated dates to the file the user selects, and the estimation procedure is completed.
Figure 4.7: File dialog for output GEDCOM file
As mentioned in chapter 1.4, the program is supposed to be for people who do not necessarily have a computing science background. Hence, the program was supposed to be fairly intuitive and easy to use. Still, a help system that would explain things in more detail was required. As the program was made in Java, the help system would also have to be platform independent. Something like a Windows help file would not be feasible. It was decided to do the help system as a set of HTML-documents. Support for reading HTML-documents is available on virtually all platforms, and HTML-documents have by nature many of the assets that are needed to do a good help system. For example, the documents may contain pictures, and they may have links to other documents.
The problems encountered during implementation with different versions of Java have been mentioned earlier. With HTML, there is also long list of potential problems once some of the newer features are used. As the help system was supposed to be fairly simple and straightforward, it was decided to only use the old, standard features, like tables, images and normal links. As a result, the help system may be read correctly by nearly all browsers that are available.
The optimal solution for the help system would be if the user did not need to have any special browser installed at all, and that the help system was totally integrated with the program with context-sensitive help. The original idea was to do this using a system called JavaHelp, made by Sun, the makers of Java itself. JavaHelp would allow the HTML documents to be integrated with the program and viewed in special windows that could be controlled to a certain degree by the program itself. However, to be able to use this, each user would have to install the JavaHelp class files on his/her computer, as well as the actual program and the Java interpreter. Also, as time was starting to run out for the project, it was not considered worthwhile to use more time on investigating this possibility. Hence, the HTML documents are rather detached from the program itself. This is not an optimal solution, but the system still fills its purpose.
The help system aims to be fairly simple and straightforward. It does not explain too much of the technical issues, e.g. how the estimation is actually done, but rather focuses on how to use the program. The system has a front page, and then separate pages for the main window in the program, the options window, the estimation process and the error messages the program might give the user. Also, there is an "about" page with information like who made the program etc.
Printout of the help system HTML documents is available as appendix C.
This chapter concerns the results the project has achieved. It starts with a general discussion of the experimentation that has been done (chapter 5.1). Then, a small example shows a small GEDCOM file before and after the program has done estimation on it (chapter 5.2), while another example proves how the program handles negative year ranges (chapter 5.3).
During development of the program, it was mainly tested against some constructed test case just to see that it actually worked. This testing is described in more detail in chapter 4.3. When the program was finished, and it was established that it did work the way it should, it was natural to do more testing or experimentation on real-life data. First of all, this experimentation ensured that the program was able to cope with larger files and databases. The constructed test cases were generally small, and doing testing with larger files gave confidence that the program could cope with just about anything. Obviously, a larger file means that the program will need more time to read it, perform estimation on it, and then write the output file. Still, even with the largest files tested, any of these tasks would be done in a second or two, so the performance certainly seems to be good. It is hard to do more scientific measuring of the performance, as the time will depend a lot on the input data, and there is not really anything to compare it with.
More important and more interesting than that program was able to cope with larger files, the experimentation proved that the program really worked on real-life data. If it was not possible to get useful results for real-life data, the program would only be of purely academic interest, but with the results the program is able to give it should be worthy of use by genealogists.
In this subchapter there is an example of how a GEDCOM file may look after the program has performed date estimation on it. Figure 5.1 shows a fictional GEDCOM file that was given as input to the program. It contains three people with identifiers I1, I2 and I3 and a family with identifier F1. I1 is the husband in the family F1, I2 is the wife, while I3 is a child in the same family. It varies a lot from person to person how much information is specified about them. For example, I2 does not have any events like birth, christening, death or burial specified at all, while I1 has all of those events specified with exact dates.

Figure 5.1: Example GEDCOM file used as input to program
As explained in chapter 2.2, the program will insert default year ranges (from 0 to 9999) for all events that are not specified at all, and translate some of the specified dates to year ranges. For example, "AFT 1824" is translated to a year range from 1824 to 9999. Then, the estimation is started. When the estimation is complete, the program will write the output file, which will contain new values for some of the dates in the input file. Events that were not specified at all will have inserted with an estimated date. However, dates that could not be estimated closer by the program than they already were will not have been changed at all. The output file is shown in figure 5.2.

Figure 5.2: Example output GEDCOM file
As the GEDCOM in figure 5.2 shows, no changes has been made to I1 who already had all events specified with precise dates. I2 had however no events specified, and birth, christening, death and burial have all been added with estimated dates. For example, the birth has been estimated to be between 1774 and 1810. For I3, the dates specified for birth and death has been changed from the way they were specified using before/after to year ranges. The burial date has not been changed, while christening date has been added with an estimate. For the family, there are no changes.
Typically, the real-life databases that were used for testing would have a small number of inconsistencies in them that would lead to negative year ranges during estimation. (See chapter 2.2 for description of how these negative year ranges can arise.) Most of the databases only had one or two inconsistencies, while the maximum number encountered was four. The experimentation showed that subsets of the original GEDCOM were removed and stored in separate files, just as they were supposed to. These subsets would in most cases consist of a very small number of individuals and families. Typically, they would be one single individual, two individuals, or one individual and one family.
Below is a small example showing how subsets are removed from a GEDCOM file. The input GEDCOM file used in the example is the one shown in figure 5.3. Of course, most real files would be a lot larger than this one, but it is easier to use a small file to illustrate this example.

Figure 5.3: Example GEDCOM file with inconsistencies
The program will encounter two negative year ranges caused by inconsistencies in this file. It will display a message box, as shown in chapter 4.4, and save subsets in separate files. The two files are shown in figure 5.4 and 5.5.

Figure 5.4: Subset of GEDCOM file containing inconsistency
When the program has identified a small subset of the file that has en error or inconsistency in it, it is much easier to identify what the problem is than if you had to look for it in the whole file. Figure 5.4 shows a subset containing two individuals, I16 and I17. I16 is a spouse in family F7, while I17 is a child in the same family. In other words, I16 is the mother of I17. Having identified this relationship between them, it is fairly easy to spot the inconsistency. I17 is born in 1865, only five years later than the mother I16. Clearly, at least one of these dates must be wrong, and the user may then go on and try to find out what is wrong. There are of course a lot of potential sources errors may arise from. Maybe a date was simply typed in wrongly when transferred from some original register, or maybe the register itself was wrong. If the user not can find out what is wrong, it is of course possible simple to delete the two dates from the input file, and then run the program again to get estimates for the dates instead.

Figure 5.5: Subset of GEDCOM file containing inconsistency
The program also identified that there is another problem in the subset shown in figure 5.5. This subset contains one individual I28 and one family F7. I28 is a spouse in F7, and again it is easy to find the inconsistency once the relationship is established. I28 apparently died before November 1900, but married after 1901.

Figure 5.6: Output GEDCOM file
As this was a very small example file and it had two errors in it, there is not much left in the output. Still, the example output file is shown in figure 5.6. Note that this file has the header information from the original input file whereas the subsets shown earlier have not. Also note that the subsets retain the original dates from the input, so that the user can figure out what is wrong. If the subset is quite large, it would probably have been better to have the estimated dates there, but for smaller subsets, the original dates should make it easier to figure out what is wrong. As the testing proved that the subsets are typically quite small, it was decided to use original dates. The output file, naturally, has estimated dates in it.
This chapter concludes this dissertation and summarises the project. Chapter 6.1 gives the overall conclusion and explains what has been achieved. Chapter 6.2 explains what has been learned by doing this project. Chapter 6.3 discusses some of the problems encountered during the project and suggests what could have been done differently. Finally, chapter 6.4 gives some ideas for future follow-on work to this project.
6.1 What has and has not been achieved
The aims for the project have to a very large extent been met. The program produced is able to estimate missing dates in a genealogical database as well as one can expect it to. It does have a simple and easy-to-use Graphical User Interface (GUI) although the quality of the GUI is perhaps not as high as wanted (ref. chapter 4.1). However, a help system was developed to aid users with less computer experience. Although the system was not integrated with the program, it still provides users with all information they should need to be able to use the program on their real-life data (ref. chapter 4.5).
When it is not possible to give a reasonable estimate for a missing date in the database, the program is able to identify the subset of the database that is causing the problem, save this in a separate file, and continue estimation on the remaining data. To deal with such error situations was an important part of the project, and the way it has been solved can be considered very satisfactory.
The program has been tested with a number of real-life GEDCOM files from a number of different genealogical software packages. This experimentation was important to see that genealogists who need to do date estimation may actually use the program for this purpose. Some very simple statistics about the number of negative year ranges encountered were compiled (see chapter 5.3). Still, some more extensive experimentation should preferably have been done. Particularly, it would have been useful to compile some statistics about the year ranges in the output file. That would have been a quite time-consuming operation, and there was not enough time to do so in this project.
This project has certainly been a good learning experience. Skills in the technologies used, particularly UML and Java, were already acquired through other modules, the group project undertaken at Stage 2, and also through paid summer jobs. However, to practice something is always likely to increase the skills, so even the skills in these technologies have improved during the project. The most important learning experience has however been related to doing such a substantial project alone. To make most decisions related to the project alone is certainly different from all substantial projects done earlier, as they have been group projects. It requires good insight into the problem to take a decision and equally well it requires determination and self-discipline to keep up with the work during the project. However it has to be said that the supervisor for the project has been very helpful in suggesting solutions to problems, and hence reducing the burden of having to take all the decisions.
6.3 What could have been done different
Every project of this size is likely to run into some problems on the way. The most substantial problem in this project has been to keep up with the planned project schedule. In particular, the project plan did not really take into account that some periods are very busy because of coursework in other modules, especially the last few weeks before Christmas and also some of the weeks before the Easter break. The project plan should have taken this into account to a greater extent. Another reason for the problem of following the plan is the of experience in estimating how long various tasks are going to take. Although that problem could perhaps have been reduced by doing some research on time estimation techniques at the start of the project, there is nothing replacing real experience in this area. Hence, this will probably have to be treated as a learning experience.
Some of the other problems encountered had to do with more specific details about Java, as explained in chapter 4.1. Problems like these are almost inevitable, and would be really hard to avoid by better planning.
The experimentation done for the project was as mentioned not as extensive as it could have been. It would be very interesting to see some statistics about the year ranges in the output file, e.g. how many of them were inserted, how many of the original ones were changed, what is the average and maximum year range etc. As mentioned in chapter 6.1 this was not done, as it would have been a quite time-consuming operation to compile the date manually. An alternative would be to extend the program to compile such data as it did the estimation and then display the statistics in a message box when the estimation was complete.
As mentioned, it would probably have been possible to make a better GUI if the Java 2 platform had been used. It was not used because it is not yet supported on MacOS and a number of other operating systems, but these systems are likely to support the Java 2 platform at some point. When they do, it could be a good idea to re-write parts of the GUI to use some of the new features available.
The estimation done in the program is as such a fairly complete, and it is hard to see any major extensions to the program, unless it is to be developed into a complete genealogical software package. It would probably be a better idea to think of ways this program can be integrated more closely with popular genealogical software packages that already are available. As mentioned, a part of the goal for the program has been to make it as general as possible, independent of both operating system and other software. That does not prevent anyone who wishes to do some integration. There is a command-line version of the program available, which does not require any interaction from the user, and which has exactly the same estimation procedure as the GUI version. Given a genealogical system with some sort of scripting facility, it could be possible to make a script that exports the data from that system to GEDCOM, executes date estimation on that file with the program made in this project, and then imports the resulting file into the system again. Hence, the whole date estimation could be available by clicking a single button.
1. David Hawgood, GEDCOM Data Transfer, 3rd ed., Cardan 1999
2. Edith Chipo Lwanda, Date Estimation in Genealogical Databases, University of Newcasle upon Tyne 1992
3. David Flanagan, Java in a Nutshell, 2nd ed., O’Reilly 1997
4. Sinan Si Alhir, UML in a Nutshell, O’Reilly 1998
1. Sun’s Java Development Kit, version 1.1
http://java.sun.com/products/jdk/1.1/
2. Sun’s Java 2 Platform
http://java.sun.com/j2se/
3. Apple’s MacOS Runtime for Java (MRJ)
http://www.apple.com/java/
4. The Blackdown Java-Linux port
http://www.freshports.org/java/linux-blackdown-jdk14/
Below is a list of the appendices that follow this dissertation. Each appendix has a front page with some more explanation.
Printout of the Javadoc HTML documents generated for the Java classes
Complete listing of source code for the program
Printout of the HTML documents developed as a help system for the program
The original project specification