CSC8332 - Bio-data science - Multi-dimensional data visualisationDr. Paweł Widera
March 2024
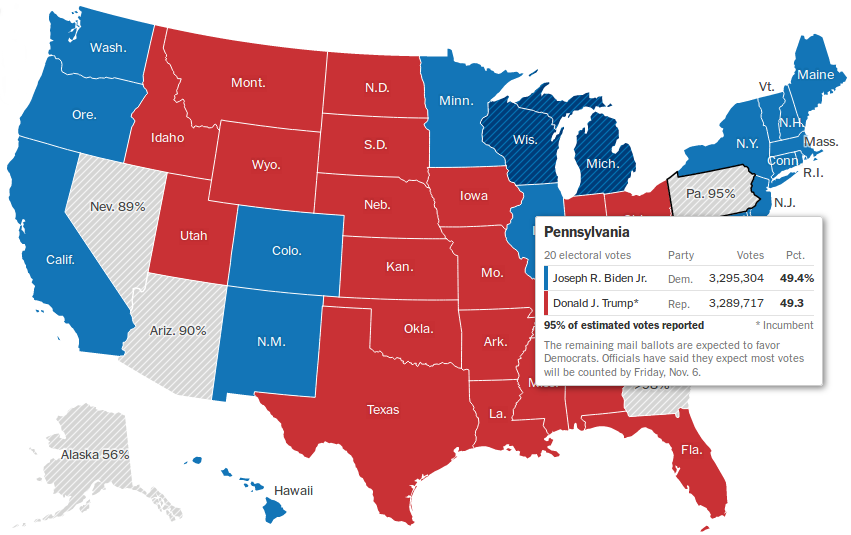
Presidential elections - trends
Datasets
wheat varieties + 1
mushrooms +1
heart failure study +1
3
What will we do?
multi-panel plotsnetwork visualisation
seaborn functions
figure-level functions plot-level functions
------------------------ --------------------------------------------------
displot histplot, kdeplot
catplot stripplot, swarmplot, boxplot, violinplot, barplot
relplot scatterplot, lineplot
lmplot regplot
JointGrid PairGrid FacetGrid
Joint grids
data = pandas.read_csv("data/wheat_processed.csv")
grid = seaborn.JointGrid(x="width", y="length", data=data)
grid.plot_joint(seaborn.scatterplot, alpha=0.5, edgecolor="b")
grid.plot_marginals(seaborn.kdeplot, fill=True)
grid.savefig("results/figure.png", dpi=150, bbox_inches="tight")
grid = seaborn.JointGrid(x="width", y="length", hue="variety", data=data)
grid = seaborn.JointGrid(x="width", y="length", data=data)
grid.plot(seaborn.regplot, seaborn.boxplot)
data = pandas.read_pickle("data/mushroom_processed.pkl.gz")
grid = seaborn.jointplot(x="habitat", y="cap_color", kind="hist", data=data)
grid = seaborn.jointplot(x="habitat", y="cap_color", hue="kind", kind="hist", data=data)
Pair grids
data = pandas.read_csv("data/wheat_processed.csv")
columns = ["area", "perimeter", "compactness", "asymmetry"]
grid = seaborn.PairGrid(vars=columns, data=data)
grid.map_diag(seaborn.histplot)
grid.map_offdiag(seaborn.scatterplot)
columns = ["width", "length", "compactness", "asymmetry"]
grid = seaborn.PairGrid(vars=columns, hue="variety", data=data)
grid.map_diag(seaborn.histplot, multiple="stack", element="step")
grid.map_offdiag(seaborn.scatterplot, size=data.area)
grid.add_legend(title="", adjust_subtitles=True)
data = pandas.read_pickle("data/mushroom_processed.pkl.gz")
columns = ["habitat", "cap_color", "cap_shape"]
grid = seaborn.pairplot(vars=columns, kind="scatter", diag_kind="hist", data=data)
for plot in grid.axes[-1]:
for label in plot.get_xticklabels():
label.set_rotation(30)
Facet grids
data = pandas.read_pickle("data/heart_processed.pkl.gz")
grid = seaborn.displot(x="serum_sodium", hue="sex", multiple="dodge", data=data)
grid = seaborn.displot(x="serum_sodium", hue="sex", col="smoking",
multiple="dodge", data=data)
grid = seaborn.displot(x="serum_sodium", hue="sex", col="smoking", row="hypertension",
multiple="dodge", data=data)
grid = seaborn.FacetGrid(data, col="diabetes", row="hypertension")
grid.map(seaborn.scatterplot, "serum_sodium", "ejection", size=data.age)
grid.add_legend(title="age")
grid = seaborn.FacetGrid(data, col="diabetes", row="hypertension", hue="died")
Graph construction
data = pandas.read_csv("data/wheat_processed.csv")
data.groupby("variety").describe()["area"]
import itertools
# find pairs of seeds with similar area (1% tolerance)
edges = [(a, b) for a, b in itertools.combinations(data.index, 2)
if (data.area[a] - data.area[b]) / min(data.area[a], data.area[b]) <= 0.01]
import igraph
graph = igraph.Graph(edges=edges)
igraph.plot(graph, "results/network.png", layout="kk")
igraph.plot(graph, "results/network.png", bbox=(1280, 960), layout="kk")
Graph attributes
import seaborn
colours = [seaborn.color_palette("deep")[i - 1] for i in data.variety]
graph.vs["color"] = colours
graph.es["color"] = "#99999933"
degrees = graph.degree()
graph.vs["size"] = 10 + 2 * pandas.qcut(degrees, 8, labels=False)
for e in graph.es:
if colours[e.source] == colours[e.target]:
e.update_attributes({"color": colours[e.source]})
Graph layouts
igraph.plot(graph, "results/network.png", bbox=(1280, 960), layout="circle")graphopt, lgl, drl, mds, fr, rt, rt_circular
import random
random.seed(31)